S3 migration with chorus

An S3 system holds data—call it source. It keeps applications running, but migration is needed, maybe due to scale limits or costs creeping up. A new S3 setup, target, is set to replace it. The challenge is to move all data from source to target with no downtime, no data lost, and no breaks for the apps using source. What can get this done?
What Are the Challenges?
Migrating S3 data brings several key difficulties:
- Data and Metadata Consistency: It’s essential to make sure that all data is copied correctly—no objects lost or corrupted. Besides this, applications relying on metadata (e.g., ACLs, versions, timestamps) need to keep working as expected, so that metadata has to be spot-on too.
- Ongoing Writes: Applications don’t stop writing to
sourcestorage during migration, and all that new data needs to reachtargetstorage too. Synchronous replication sounds good but can get slow and messy—what’s the right response to a user if aPUTworks onsourcestorage but flops ontarget? The alternative is downtime: pause writes tosourcestorage and copy everything at once. For some applications, though, downtime just isn’t an option.
These issues don’t stand alone—they tangle together. Verifying data integrity gets tricky when ongoing writes shift the dataset mid-migration.
Regarding Tools and Strategies
Two high-level approaches can tackle these challenges:
- Do It Bucket by Bucket: This approach leans on a canary deployment strategy. Copy one bucket, switch the application to
targetstorage, and check if everything runs as expected. If it does, move on to the next bucket; if not, flip back tosourcestorage and dig into the problem. It cuts downtime too—copy a bucket at a time and switch the application only when all data’s in place. - Do It in Two Phases: Say a bucket holds 10 million objects, and copying takes a day. During that time, ongoing writes mean about 5% of objects get added, updated, or removed. So, copy all the data once without stopping writes. Then, use a short downtime to figure out which objects changed and copy just those. Call the first pass
initial replicationand the secondevent replication.
These ideas sound simple, but execution isn’t. Questions arise:
- If applications expect one URL for all buckets, how does bucket-by-bucket work?
- How can writes to one bucket be stopped for downtime?
- How are changes (aka events) tracked for
event replication? - How can 10 million objects be copied fast enough?
- How does this scale to 10,000 buckets automatically?
Now, let’s see how Chorus handles these challenges and strategies.
How Chorus Works
To let applications use buckets from both source and target storage via a single URL and credentials, Chorus offers a Proxy. This proxy does more than route:
- Routes requests by bucket name, unifying access across storages.
- Resigns requests to use one credential set for both storages.
- Blocks writes to a bucket when downtime is triggered.
- Captures changes during
initial replicationas events, storing them in aqueueforevent replication.
For fast data copying, Chorus runs a separate Worker services across multiple machines.
Worker responsibilities include:
- Listing
sourcebucket objects to fan out copy object tasks intoqueueforinitial replication. - Process copy object tasks from
queuein parallel to migrate payload and metadata. - Process event tasks generated by
Proxyto copy changes forevent replication. - Expose API to programmatically start, stop, pause, and check bucket replication status.
- Expose API to manage routing by bucket to start/stop downtime or switch to
targetstorage.
Both Proxy and Worker are stateless, horizontally scalable services. Redis is used as a shared state store and task queue. It holds metadata, events, and tasks, enabling Proxy and Worker to scale independently.
Diagram below shows Chours components and their interactions during bucket initial replication:
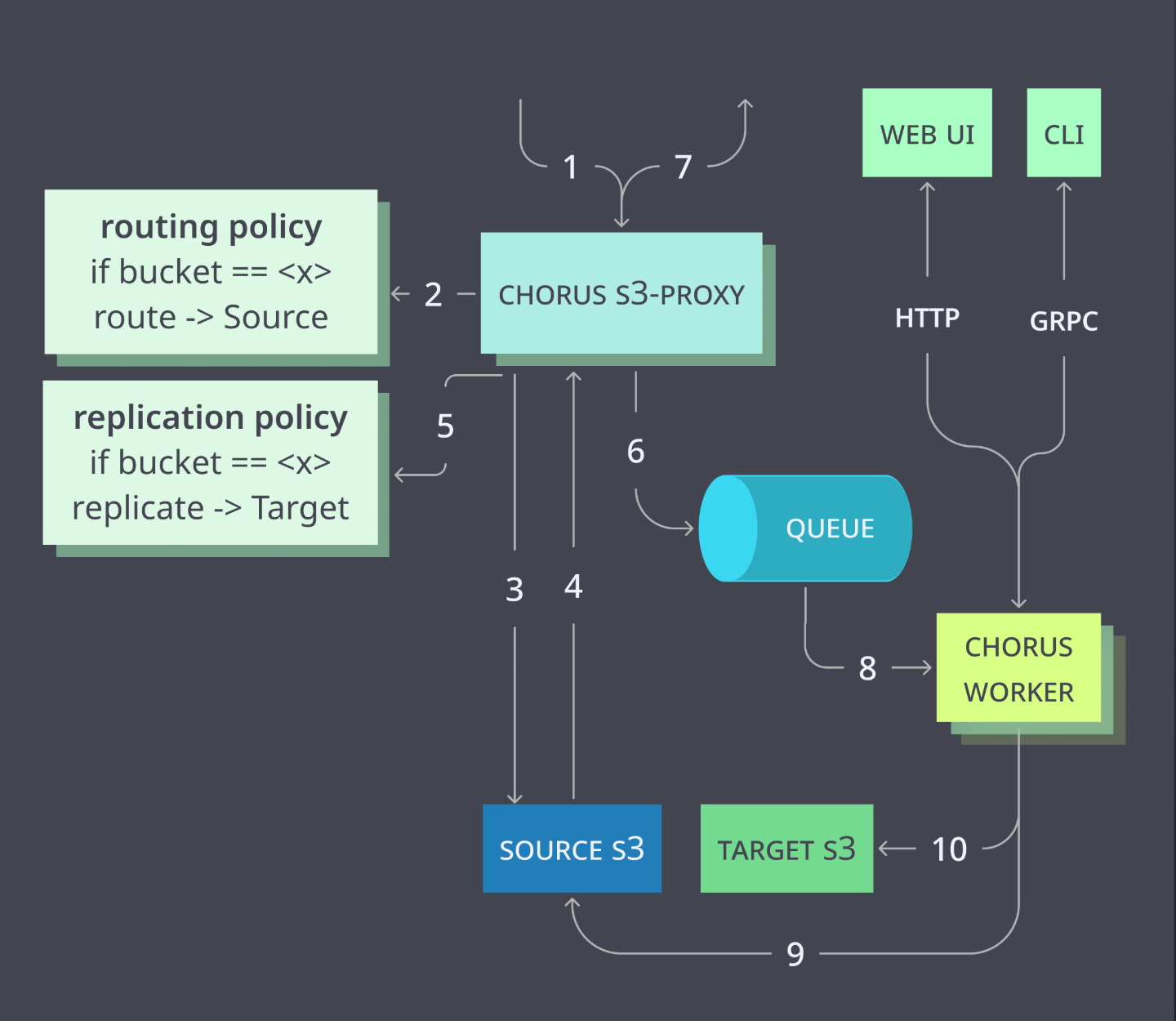
Proxy routes S3 request to source (steps 1-4) and if it was a successful write request, it emits event to the queue (steps 5-6) and returns response to the client (7). Workers asynchronously pick up events from the queue to sync object from source to target storage in parallel (steps 8-10).
User can monitor task progress in initial and event replication queues. When initial replication is done, Chorus API allows to schedule downtime window to drain event queue and switch bucket to target storage or even do it without downtime.
What? Chorus can migrate S3 bucket without downtime? But how? And why offer a downtime option then?
Nothing’s free—zero downtime comes with trade-offs. Let’s break down both approaches in Chorus.
Migration with downtime window
Migration with downtime is a straightforward implementation of Two-Phase Migration strategy from the start of the article.
Here user already started replication for the bucket and all existing objects were migrated in initial replication phase. Simplified diagram shows handling downtime window:
- Steps
1-3: Ongoing reads and writes (RWrequest) tosourcestorage with capturing data changes toevent replicationqueue. - Steps
4-5: Writes get blocked to drain theevent replicationqueue (step6). Draining means completing all tasks till it’s empty. - Steps
7-9: The bucket’s synced betweensourceandtarget, andWorkerverifies contents. - Step
10:Proxyswitches routing totargetstorage and unblocks writes. - After verification,
Proxyswitches routing totargetstorage and unblocks writes10. - Steps
11-12: All requests now flow totargetstorage.
Terms like tasks, qeueue, and events were mentioned several times in context of Chorus bucket migration.
But what exactly happens when proxy creates a task in event replication qeueue and how worker processes it?
- For
initial replication,workercreates a task for every object. It puts task ininitial replicationqueue. - For
event replication,proxycreates a task for every object change, sent to a separateevent replicationqueue. - Having two separate queues allows to prioritize
initial replicationtasks overevent replicationtasks. And easily detect when each phase is done. - Each task has the same payload:
- Changed object key.
- Source and target storage names.
- Task has no information about the change itself. When
Workerreceives tasks, it:- does
HEAD objectrequest tosource - if object not exists, it removes it from
target - otherwise, it compares objects ETAG with
targetand updates object if needed.
- does
Described approach allows having correct results even when tasks are duplicated or processed out of order.
Planning Downtime Window
Chorus API allows to schedule bucket downtime window to specific time and also set a timeout for it. If migration will not be completed in time, it will be automatically cancelled and rollback to source storage will be performed.
Window schedule can be set with CRON expression to attempt it multiple times.
It is also possible to set a max event replication queue size for downtime window. Downtime window attempt will be skipped if queue has too many unprocessed tasks.
Zero-Downtime Migration
Above is detailed and correct explanation of how Chorus creates and processes tasks for bucket migration. But it intentionally missing one important detail allowing to do migration without downtime.
Chorus maintains its own metadata of object versions in source and target storage. Metadata is stored in Redis as version vectors:
- For each object change event Proxy also increases object version for routed (
source) storage. - When
Workerprocesses event task, it:- reads version for
sourceandtargetobjects - skips task if
source <= target - otherwise, updates object in
targetstorage and setstargetversion equal tosourceversion.
- reads version for
This approach helps to reduce API calls and deduplicate object change events. But most importantly, it allows to do migration without downtime.
When zero-downtime starts, proxy immediately routes all write requests to target storage.
Then it uses object version metadata in Redis to correctly route read requests to S3 storage with the latest object version as shown in the diagram below:
Two Approaches Compared
By closely inspecting both diagrams we can mention key differences:
- Zero-downtime has no data verification step. Makes sense—there’s no moment when
sourceandtargetmatch up:- Before the
eventqueue drains,targetstorage misses changes fromsource. - After it drains,
sourcestorage misses writes routed totargetduring that time.
- Before the
- If something goes wrong during
zero-downtimemigration, rolling back tosourcestorage loses writes made during migration—no clean undo like with downtime.
Potential data loss is the primary trade-off for zero-downtime migration. This aligns with IT Disaster Recovery principles, relevant for strategy selection. Two metrics apply:
- Recovery Time Objective (RTO): How long it takes to recover after a disaster. How long system will be unavailable.
- Recovery Point Objective (RPO): How much data can be lost. How much data will be lost after recovery.
While migration isn’t a disaster, it’s a critical operation requiring careful planning due to possible software or hardware failures. Evaluate RTO and RPO per bucket:
- Downtime Window migration focuses on minimizing RPO. It performs data integrity check and allows to rollback in case of any failure without data loss. But downtime window will make system unavailable for some time making non-zero RTO.
- Zero-Downtime migration focuses on minimizing RTO. If everything goes as planned, system will be available all the time and all data will be migrated correctly giving zero RPO and RTO. But in case of failure and rollback to
sourcestorage, all writes happened during migration will be lost giving non-zero RPO.
Next Steps
With Chorus’s mechanics clarified, proceed to the Usage Guide. It provides executable, step-by-step instructions and a local setup to explore Chorus hands-on.